From Questions to Insights: Unlocking the Power of ACS with AI
Simplifying Complex Data Access with Natural Language and Intelligent Automation

The Power and Complexity of the American Community Survey (ACS)
The American Community Survey (ACS) is a vital resource from the U.S. Census Bureau, providing detailed demographic, economic, and housing data. Its insights are invaluable for social and healthcare researchers, especially as social determinants of health—factors like income, education, and housing—are increasingly integrated into clinical studies.
Despite its value, the ACS dataset’s size—over 20,000 variables—makes it difficult to navigate. Existing tools, like the ACS API, require technical expertise, creating a barrier for non-technical users who could benefit from this data. Simplifying access to ACS data is essential to empower broader use in public health, social policy, and evidence-based decision-making.
Simplifying ACS Data Access with AI-Powered Solutions
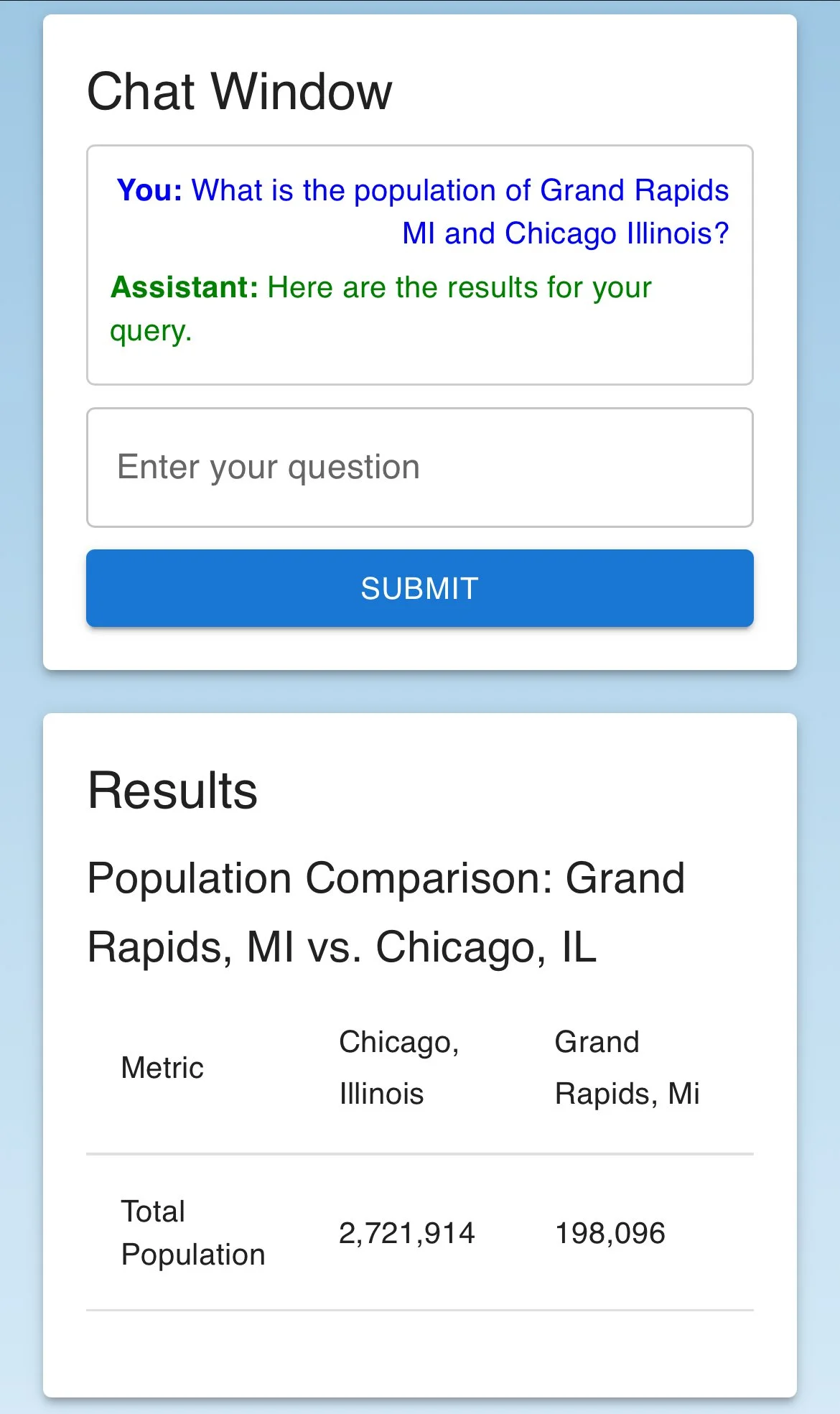
I’ve developed a solution to bridge the gap between the American Community Survey’s complexity and the researchers who need its data. By leveraging artificial intelligence and large language models (LLMs), I’ve created an intuitive natural language interface that allows researchers to query the ACS without requiring technical expertise.
The core idea was simple but powerful: users could ask questions in plain language, and AI would handle the rest. The system discerns the intent behind each query, identifies the relevant API parameters from over 13,000 options, and constructs the necessary API calls. This approach removed the challenge of knowing which variables to request, how to format queries, or how to retrieve data accurately.
Streamlining Data Access with Agentic AI
Natural Language Interface
LLMs for Parsing Intention and Locations
Dynamic API Construction
Data Retrieval
User-Friendly Presentation
Once the data is retrieved, it is presented in a user-friendly format, allowing researchers to focus on insights rather than the mechanics of data access. By automating the selection and execution of API calls, this solution made ACS data accessible to a broader audience, enabling faster and more effective integration of social determinants of health into research and policy decisions.
Example - Count of Service Workers Walking to Work in Michigan:
https://api.census.gov/data/2022/acs/acs5?get=NAME,B08124_031E&for=state:26
Background on the ACS API
The ACS API provides metric data for over 20,000 variables, organized into 635 concepts, such as Means of Transportation to Work by Occupation. Each variable represents a specific data point, like B08124_031E ("Estimate!!Total:!!Walked:!!Service occupations").
Data is accessible at city, county, and state levels using PLACEFP, COUNTYFP, and STATEFP codes.
Each API call retrieves data for a single location, returning results in JSON format for further processing. While efficient for technical users, the API's complexity makes it challenging for non-technical users to access and utilize, especially with such an incredibly fine level of detail.
Technologies and Architecture
To build my solution, I leveraged Azure cloud services to create a scalable and low-complexity architecture. The front end is hosted on an Azure Static Web App, providing simplicity and reliability. It was developed using React with Material UI, ensuring a clean, user-friendly interface for seamless interaction.
The back end is powered by an Azure Function in Python, which offers a serverless and highly scalable approach for handling all computational tasks. It processes user queries by executing analysis, calling LLMs hosted by ChatGPT, and interacting with an Azure SQL Database. This database stores essential reference data, including API metadata, location codes, and a keyword dictionary to support accurate query interpretation.
For integration and deployment, I utilized GitHub CI/CD to streamline code management. This setup automates builds, facilitates rapid testing, and enables continuous improvement, ensuring a robust and efficient development pipeline.

Putting It All Together
The AI agent’s workflow is designed to transform natural language queries into actionable API calls seamlessly. When a user submits a query through the front-end interface, the system uses an LLM (Chat GPT-4o-mini) to process the query, extracting the user’s intent and identifying meaningful data points. The LLM selects the most relevant API codes to address the query, leveraging a keyword dictionary stored in an Azure SQL database to map user terms to the appropriate variables.
To handle location-specific requests, the SQL database is also queried to retrieve the necessary location codes (such as PLACEFP, COUNTYFP, and STATEFP). With the API codes and location parameters identified, the agent constructs the required API calls. These calls are executed to retrieve data, which is then processed and returned to the user in a clear, user-friendly format. This workflow simplifies complex queries, ensuring precise results while eliminating the need for technical expertise.

Logic Behind Using LLMs to Identify the Correct API Codes
Using LLMs to identify the correct API codes for a user’s query involves several key steps and challenges. Initially, I used an LLM to extract the user’s intent, keywords, and location information from their query. This part was straightforward, as the LLM efficiently identified relevant terms and geographies. The real complexity arose when determining which API codes from the extensive database were most appropriate to answer the query.
With over 20,000 API codes covering various topics, I needed a strategy to narrow the potential matches. My first approach was to group codes by their concepts, but the 635 unique concepts were still too broad. To simplify, I manually categorized these concepts into 13 higher-level categories, such as Education, Income, and Transportation, which allowed me to exclude large sections of irrelevant codes early in the process.
I needed finer granularity to improve matching accuracy even with categories in place. I used the NLTK library to extract keywords from the API name, concept, and category descriptions to achieve this. This provided a foundational keyword list for each API code. To expand these lists, I leveraged an LLM to generate synonyms for each keyword in the context of the ACS database. For example, the database used “male,” so I added synonyms like “man” and “men.” Similarly, for “college,” I included terms like “university” and “secondary education.” This enhanced keyword matching significantly reduced the number of candidate API codes.
Despite these improvements, category and keyword matching alone sometimes left hundreds of potential matches for queries like “What is the Hispanic population of Michigan?”, which would return over 1,000 potential API codes.
To refine the results further, I employed a recursive LLM prompt strategy. I split the list of candidate codes into manageable “chunks” that fit within the LLM’s context window. Each chunk was processed by the LLM, which filtered out only those codes whose descriptions aligned with the user’s query. By repeating this process recursively, I reduced the list to a maximum of 30 codes.
One critical challenge I faced was the 45-second computation time limit of the Azure Function running my analysis. This constraint required optimizing the chunk size to balance context processing time, LLM latency, and compute limits. After testing, I found that a chunk size of 300 codes struck the optimal balance, allowing the system to process queries efficiently within the time limit.
This multi-layered approach—combining categories, expanded keyword matching, and recursive filtering with LLMs—enabled the system to accurately identify the best API codes for a wide variety of user queries while staying within performance constraints.
Derived Categories
Education: Refers to educational attainment, school enrollment, and literacy rates.
Disability: Includes data on individuals with disabilities and their impact on daily life or employment.
Population: Covers total population counts, age, gender, and density.
Transportation: Includes commuting patterns, travel times, and vehicle ownership.
Household and Family: Focuses on family size, household types, and housing arrangements.
Geographical Mobility: Refers to movement between geographic locations and migration patterns.
Race and Ancestry: Includes racial and ethnic groups, ancestry, and cultural heritage.
Employment: Relates to work-related information such as employment status, industries, and occupations.
Marriage and Birth: Covers marital status, births, and family formation trends.
Language: Includes data on languages spoken at home and English proficiency.
Poverty: Refers to data on individuals living below the poverty line and economic hardship indicators.
Income: Focuses on earnings, household income, and income inequality.
Age: Refers to the age distribution of the population. Includes race and gender information.
Lessons Learned: Integrating LLMs
This project was my first experience integrating LLMs into my code, and I was impressed by their ability to handle complex tasks with discernment. One key lesson was the importance of structured output. I could integrate LLM outputs into my control logic by using strict JSON responses. While inconsistencies required fine-tuning, experimentation allowed me to catch and resolve most errors. In some cases, I added additional prompts to correct issues dynamically, such as refining ambiguous user queries to keep the workflow on track.
I also used LLMs throughout the process to evaluate whether intermediate results aligned with the user’s original intent. This ability to continually assess progress against the query ensured that the solution stayed on course and delivered meaningful results. By validating outputs at each step, I could detect and resolve deviations early, enhancing the overall reliability and accuracy of the system.
Fine-tuning prompts proved essential for balancing strictness and inclusivity. For example, I relaxed an overly strict API filtering prompt to ensure users received actionable results, even if slightly broader than necessary. LLMs also helped rename long, technical metric labels into concise, user-friendly titles, improving the clarity of the output.
Overall, integrating LLMs taught me the value of structured outputs, iterative validation, and dynamic error handling to ensure functionality, alignment with user intent, and a positive user experience.
Final Thoughts and Future Enhancements
This solution effectively simplifies access to the ACS database, making it more accessible to non-technical users. As a proof of concept, I am satisfied with its performance, but there is room for improvement.
One key limitation was the computation limit of the Azure Function. Moving to a more robust architecture or implementing a queued processing strategy would allow for more computation time, improving results for complex or ambiguous queries.
Enhancing keyword matching with advanced semantic strategies could improve accuracy, particularly in challenging data areas. Adding analytics and visualization tools would enable deeper insights and comparisons, while interactive LLM feedback could better clarify ambiguous queries. Additionally, allowing users to export results into formats like Excel or CSV would make the system more versatile.
I also observed that the LLM occasionally provided inaccurate results. Since this tool is intended for research purposes, maintaining a high degree of integrity in the results is critical. Future iterations will focus on reducing errors and ensuring the accuracy of all outputs, building a solution researchers can trust for their work.
Thanks for reading!
-Michael